Aujourd'hui le BlogDuWebdesign vous propose une sélection de deux ressources vous permettant de faire de la reconnaissance optique de caractères (OCR) en Javascript.
Qu'est-ce que l'OCR ?
La reconnaissance optique de caractères (ou optical character recognition, d'ou le OCR), est un ensemble de procédés informatique permettant de convertir un texte sous la forme d'image (issu d'un scanner par exemple) en un texte sous forme de… texte, que vous pourrez éditer dans tout logiciel comme Word (ou Vim).
Ces logiciels sont évidemment extrêmement utiles pour éviter d'avoir à transcrire de très longs textes comme par exemple d'anciens livres imprimés avant la démocratisation des ordinateurs, mais les étudiants peuvent aussi l'utiliser pour transcrire des cours manuscrits par exemple.
Enfin, pour recentrer sur le web, l'OCR est par exemple capable de décrypter un formulaire que vos visiteurs auraient imprimé et complété, pour ensuite effectuer des actions en fonction de leurs réponses.
Pour illustrer cette description, je vous propose d'aller essayer directement le procédé sur le site de la ressource Ocrad.js .
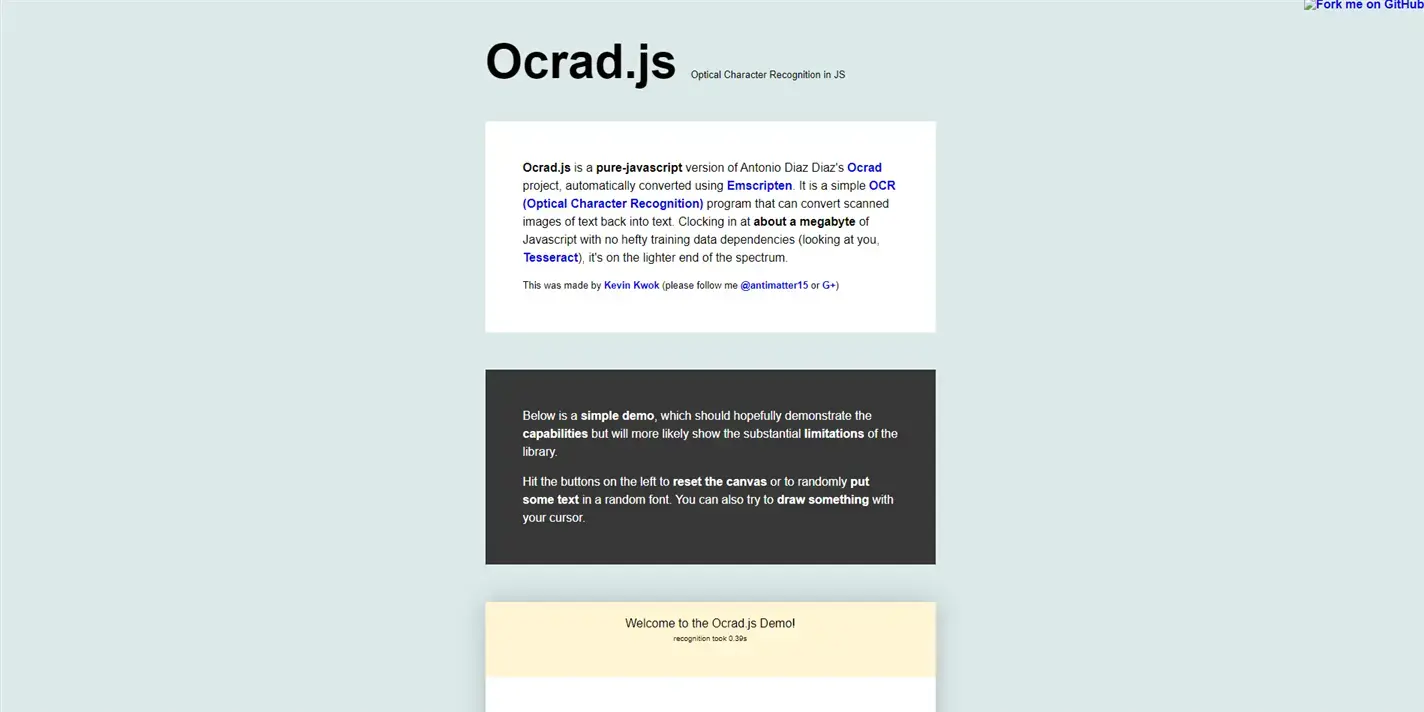
Ocrad.js
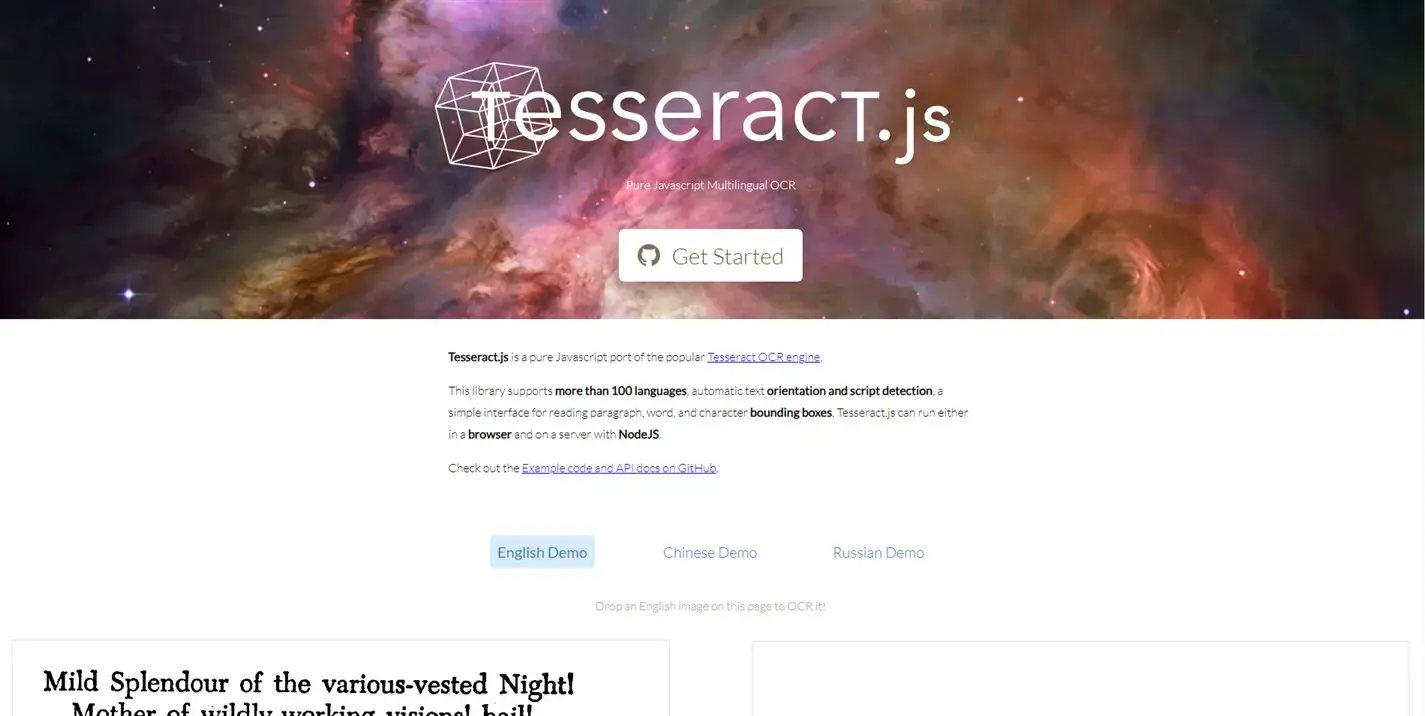
Tesseract.js
Vous connaissez peut-être Tesseract, un logiciel d'OCR développe depuis 1985, et qui a été récupéré par Google en 2006, qui le développe depuis. Contrairement à Ocrad, il est capable de reconnaître tous les caractères de l'UTF-8 et reconnaître plus de 100 langages out-of-the-box.
Tesseract.js est donc un portage de Tesseract vers le Javascript (Surprise, étonnement).
Si on devait le comparer à Ocrad, il est bien plus puissant et bien plus fiable dans sa reconnaissance, même avec du texte manuscrit ou des lettres "anciennes" et non-regulières.
Le contrecoup de cette fiabilité est évidemment un travail d'analyse plus long (comme vous pourrez vous en rendre compte avec la démo sur leur site).
-
 6 ressources pour jouer avec le scroll de vos prochains projets
6 ressources pour jouer avec le scroll de vos prochains projets
La gestion du scroll est souvent le point critique de beaucoup de sites. Le scroll de base est tr&eg... -
 Augmentez les performances de vos pages avec Perfmap
Augmentez les performances de vos pages avec Perfmap
De nombreux outils existent pour tester la vitesse de chargement de nos pages web et trouver les poi...